Как я провёл две недели в поисках утечки памяти
Предисловие
Это история о поисках утечки памяти. Она довольно длинная, потому что я привожу массу подробностей.
Почему я решил описать свои приключения? Дело не только в практическом стремлении сохранить все мелкие скрипты и куски кода. Мне на минуточку показалось, что это и есть UNIX way – то, что меня вело. Каждый шаг был связан с очередной небольшой утилитой или библиотекой, которая хорошо решает свою задачу. И я в итоге достиг успеха.
Также мне было интересно! Порой я засыпал и просыпался с мыслями о том, что происходит с памятью.
Остаётся выразить благодарность моим коллегам из компании Shuttlerock, которые работали, пока я занимался детективной деятельностью. И самой компании, конечно.
Введение
Итак, обнаружилась неприятная данность: у нашего Rails-приложения, работающего на платформе Heroku, «течёт» память. Это заметно на графике:
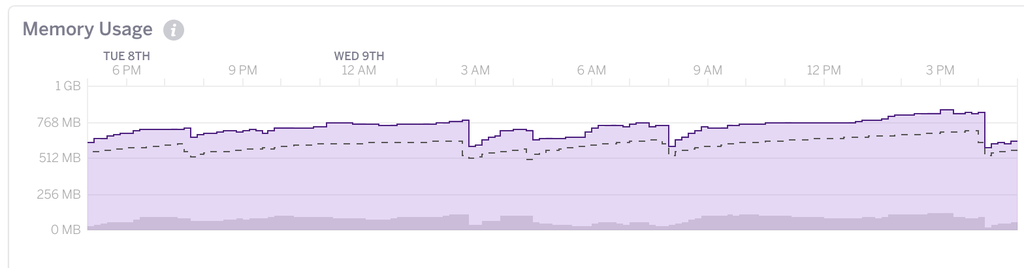
После каждого деплоя или перезапуска потребление памяти резко возрастает (см. в
районе 3 AM, 8 AM), и это нормально, ведь Ruby язык динамический. Срабатывают
какие-то require, что-то догружается. После этого потребление памяти должно
болтаться вокруг горизонтальной линии. Обработали запрос, насоздавали объектов
— вверх. Сработал сборщик мусора — вниз. По идее, в таком динамическом балансе
приложение может находится сколь угодно долго.
Однако в нашем случае на графике заметен стабильный тренд вверх. Значит, есть утечка! Наш Heroku 2X dyno (мы используем puma в кластерном режиме с 2 процессами) добирается до границы 1 Гб, после чего начинает безбожно тормозить до перезапуска.
Локальное повторение проблемы
Production-сервер — не место для экспериментов. Поэтому первое, что я сделал —
скачал дамп production-базы и запустил приложение в production-окружении на моём
тестовом Linux-сервере, стоящем в кладовке (у вас же, конечно, есть такой?). Наше
приложение — SaaS-продукт, в специальной middleware по домену определяется сайт
клиента, поэтому пришлось немного подправить код, чтобы можно было делать запросы
вида curl http://localhost:3000/…. Здесь очень удобны переменные окружения.
if ENV['QUERY_SITE_ID']
def find_site(request)
Site.find_by_id_cached(request.query_parameters[:site_id])
end
else
# Private: Look up for site.
#
# Tries to find by domain, subdomain, or use canned site in test environment.
#
# Returns Site instance or falsey value.
def find_site(request)
host = request.host
# …
end
endКак видно, если установлена переменная окружения QUERY_SITE_ID, то ID сайта
будет определяться из параметра запроса site_id:
curl http://localhost:3000/?site_id=123
Также в config/environments/production.rb понадобится поставить
config.force_ssl = false,
установить переменную DEVISE_SECRET_KEY, и возможно что-то ещё. Нужно добиваться,
чтобы приведённая выше команда curl сработала.
Итак, сервер запустился, что дальше? Теперь нужно обеспечить поток запросов. Для этого есть прекрасная утилита siege, позволяющая нагружать сервера в разных режимах и собирать статистику.
Для чистоты эксперимента я решил не долбить по одному URL, а собрать реальные адреса, по которым
заходят клиенты. Это сделать несложно: запускаем на какое-то время heroku
logs -t | tee log/production.log, потом из лога останется выкусить адреса. Я
написал для этого небольшую утилиту, которая парсила лог, собирала адреса,
site_id, печатаемые нашей middleware, и генерировала файл urls.txt в формате:
http://localhost:3000/foo
http://localhost:3000/bar
http://localhost:3000/bazТакой файл также можно сделать вручную, или воспользоваться коктейлем из awk, grep, sed.
Запускаем siege:
siege -v -c 15 --log=/tmp/siege.log -f urls.txt
Здесь siege создаст 15 параллельных клиентов и будет заходить по адресам из urls.txt.
Если всё было сделано правильно, память должна начать «течь». Это можно увидеть
с помощью утилит top, ps — соответствующий показатель называется RSS (Resident Set Size).
Чтобы не мучаться с их запуском, я добавил в приложение вот такой код:
if ENV['MEMORY_REPORTING']
Thread.new do
while true
pid = Process.pid
rss = `ps -eo pid,rss | grep #{pid} | awk '{print $2}'`.to_i
Rails.logger.info "MEMORY[#{pid}]: rss: #{rss}, live objects #{GC.stat[:heap_live_slots]}"
sleep 5
end
end
endВ логе стали появляться аккуратные записи с растущим RSS… Про GC.stat[:heap_live_slots]
см. дальше.
Позже я отказался от кластерного режима puma, потому что утечка проявлялась и в single mode, а с одним процессом проще иметь дело.
Поиск утечки в Ruby коде
Убедившись в реальности утечки, я приступил к её поиску.
Здесь нужно немного остановиться на том, как устроена память в MRI вообще. Объекты
хранятся в куче, которой управляет интерпретатор. Куча состоит из отдельных страниц размером
16 килобайт, на каждый объект выделяется 40 байт. При создании объекта идёт поиск свободной ячейки,
если таковых нет, создаётся новая страница. Конечно, не все объекты помещаются в 40 байт. Если памяти требуется
больше, дополнительная память выделяется отдельно (с помощью malloc).
Освобождение памяти происходит автоматически в процессе работы сборщика мусора (GC). Современные версии MRI имеют довольно эффективный инкрементальный GC с поколениями объектов и двумя фазами: малой и большой. Опираясь на эвристический принцип «большинство объектов имеют небольшое время жизни», малый цикл сборки мусора ищет и освобождает ненужные объекты только среди недавно созданных. Это позволяет реже запускать большой цикл, который подвергает классическому алгоритму Mark-and-Sweep ВСЕ объекты.
Нужно отметить, что для поиска утечек тонкости различных поколений совершенно не важны. Существенно одно: будут ли освобождены все объекты, порождаемые в процессе обработки запроса, или нет. Заметим, что в контексте веб-сервера все порождаемые объекты можно разделить на три группы:
- Статика. Это все загруженные гемы, особенно Rails, а также код приложения. В production-окружении всё это грузится один раз и практически не изменяется.
- Медленная динамика. Есть некоторое количество долгоживущих объектов, например, кеш prepared SQL-запросов в ActiveRecord. Этот кеш, по умолчанию имеющий размер 1000 элементов на каждое соединение с БД, будет потихоньку заполняться, и количество объектов будет расти, пока не дойдёт до предела (2000 строк * количество соединений).
- Быстрая динамика. Это все объекты, порождаемые в процессе обработки запроса и генерации ответа. После того, как ответ готов, объекты могут быть уничтожены.
Если в третьем случае какой-то объект не будет освобожден, будет утечка. Вот пример-иллюстрация:
class MyController < ApplicationController
FOO = []
def index
FOO << "haha"
end
endКонстанты не подлежат сборке мусора, и последовательные вызовы MyController#index
будут приводить к распуханию массива FOO. При этом куча будет расти из-за того,
что ячейки будут забиваться новыми и новыми строками "haha".
Если утечек нет, размер кучи будет колебаться. Минимальный размер кучи соответствует
объектам из п.1 и п.2 (см. выше). Например, у нашего приложения это чуть больше 500000 объектов
(пустое приложение сразу после rails new app даёт где-то 300000). Максимальный размер кучи
зависит от того, насколько будет успевать срабатывать большой цикл GC. Но: после
большого цикла количество объектов будет всегда возвращаться к нижней границе, которая изменяться не будет.
Утечки будут приводить к тому, что нижняя граница поплывёт вверх. Показатель
GC.stat[:heap_live_slots] как раз отражает текущий размер кучи.
Удобнее всего исследовать эти вещи с помощью гема gc_tracer, созданного Koichi Sasada, членом команды разработчиков Ruby и автором инкрементального сборщика мусора в Ruby 2.1 и 2.2. Добавив строки
require 'rack/gc_tracer'
config.middleware.use Rack::GCTracerMiddleware, view_page_path: '/gc_tracer', filename: 'log/gc.log'в config/application.rb, мы получим файл log/gc.log, который будет наполняться статистикой работы
сборщика мусора и результатами вызова getrusage (последнее полезно, потому что одно из полей содержит
интересующую нас цифру RSS).
В каждой строке этого лога около 50 значений и глаза разбегаются, однако на то есть несложная магия UNIX.
Вот команда, которую я запускал параллельно с puma и siege:
tail -f log/gc.log | cut -f 2,4,7,8,9,15,16,19,21,22,25,26,27,28,29,30,36
1441967588854360 2450 998618 997652 966 2450 0 0 5151 665 581634 1052512 2490888 16777216 0 newobj 277196
1441967588879589 2450 998618 997652 966 2450 0 0 5152 665 598912 1052512 2490888 16777216 0 newobj 277196
1441967590064377 2450 998618 997618 999 2450 0 503688 5152 665 598912 1052512 2103264 16777216 0 newobj 277196
1441967590064684 2450 998618 997808 810 2450 0 0 5152 665 598912 1052512 2107280 16777216 0 newobj 277196
1441967590088032 2450 998618 997808 810 2450 0 0 5153 665 613199 1052512 2107280 16777216 0 newobj 277196Самое первое значение в строке — timestamp в миллисекундах. Второе — количество страниц. Третье — общий размер кучи в единицах объектов. Одиннадцатое (581634…613199)— количество «старых» объектов, т.е. тех, которые не обрабатываются в малом цикле сборки мусора. Самое последнее — RSS.
Но даже так цифр слишком много. Что ж, построим график! Конечно, лог можно непосредственно загнать в Excel (простите, LibreOffice Calc), но это не наш путь. Гораздо лучше воспользоваться gnuplot, который умеет рисовать графики прямо из файлов.
К сожалению, gnuplot не поддерживает формат времени с миллисекундами, поэтому пришлось написать маленький скрипт для преобразования времени:
#!/bin/sh
cat $1 | awk \
'{if($1=="end_sweep"||FNR==1) {if(FNR>1) {$2=substr($2,1,length($2)-6)} else {$2=$2}; print $0}}' > $2Помимо приведения временных отсчётов к секундам здесь отбрасывается лишняя информация. gc_tracer генерирует данные на всех фазах работы сборки мусора, но нас будет интересовать только конец (end_sweep).
С помощью вот такого gnuplot-скрипта:
set xdata time
set timefmt '%s'
set format x '%H:%M'
set y2tics on
set y2label 'Kilobytes'
set ylabel 'Objects'
plot 'gc.log.22' using 2:25 with lines title columnhead, \
'' using 2:36 with lines lc rgb 'blue' title columnhead axes x1y2получаем картинку:
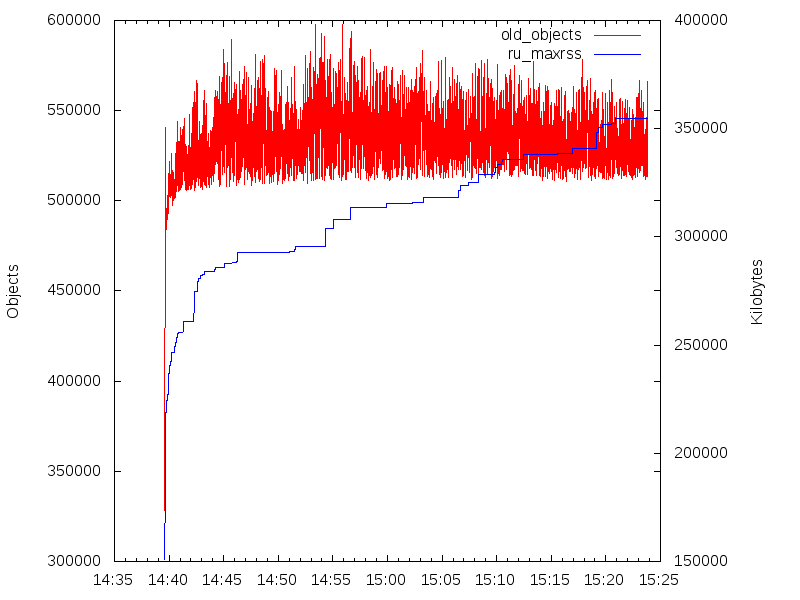
Красная кривая (левая шкала) — количество «старых» объектов. Оно ведёт себя так, будто никакой утечки памяти нет. Синяя кривая (правая шкала) — RSS. А оно растёт…
Вывод простой: в Ruby коде утечек нет. Однако я не сразу догадался до этого и сходил еще по ложному пути, не приведшему к результату.
Ложный путь. Возня с дампами кучи
Современные версии MRI оснащены мощнейшими средствами анализа работы с памятью. Например, можно включить трассировку создания объектов, и для каждого вновь создаваемого объекта будет сохранено место (имя файла и номер строки), в котором он был создан:
require 'objspace'
ObjectSpace.trace_object_allocations_startТакже можно сделать полный дамп кучи в файл:
File.open("my_dump.txt", "w") do |f|
ObjectSpace.dump_all(output: f)
endДля объектов, созданных после включения трассировки, в дамп попадет информация о месте создания объекта. Сам дамп представляет собой файл в формате JSON Lines: данные о каждом объекте представлены в формате JSON и расположены на отдельной строке.
Уже появились гемы, использующие возможность трассировки, например, memory_profiler и derailed. Вот и я решил поисследовать, что в нашем приложении происходит с кучей. Не добившись внятного результата от memory_profiler, я решил сгенерировать и проанализировать дампы сам.
Поначалу я написал свой бенчмарк аналогично тому, как сделано в derailed,
но потом перешел на генерацию дампов из живого приложения с помощью rbtrace.
Если в Gemfile есть gem 'rbtrace', то дамп может быть сгенерирован следующим образом:
rbtrace -p $PID -e 'Thread.new{GC.start;require "objspace";File.open("heapdump.jsonl", "w"){|f| ObjectSpace.dump_all(output: f) }}'Теперь предположим, что у нас есть три дампа (1, 2, 3), сгенерированные в разные моменты времени. Как распознать утечку? Для этого предлагается следующая схема: возьмём дамп 2 и уберём из него все объекты, которые уже встречались в дампе 1. После этого уберём из него все объекты, которых нет в дампе 3. То, что останется — объекты, которые, возможно, «утекли» во время, прошедшее между созданием дампов 1 и 2.
Я даже написал свою утилиту для описанного дифференциального анализа дампов. Она реализована на… Clojure, потому что мне нравится Clojure.
Всё, что обнаружил анализ, — это упомянутый выше кеш prepared SQL-запросов. Его содержимое — строки с запросами — вовсе не «утекли», просто они прожили достаточно долго и проявились в дампе 3.
Таким образом, я окончательно убедился, что утечек памяти в Ruby коде нет, и был вынужден искать утечки в другом месте.
Знакомство с jemalloc
Я сформулировал следующую гипотезу: если в Ruby утечек нет, но память куда-то девается, возможно, утечки есть в каком-то коде на C. Это либо native code гемов, либо сам MRI. В таком случае C-куча должна расти.
Но как искать утечки в C? Первое, что я попробовал, это valgrind и утилита leaks
под OS X. Они ничего интересного не нашли. И тогда поиски привели меня к jemalloc.
jemalloc – это кастомная реализация malloc, free и realloc, которая пытается быть эффективнее стандартной
системной (не считая FreeBSD, где она и является системной). Для этого применена масса
трюков. Там и своя система страниц с выделением через mmap, и разделение аллокатора на независимые «арены»,
к которым привязываются потоки; независимость позволяет избежать межпотоковой синхронизации. Выделяемые блоки
разделяются на три класса по размеру: small (< 3584 байт), large (< 4 Мб) и huge –
для каждого класса память выделяется по-особенному. Но,
что самое важное, — в jemalloc есть сбор статистики и профилировка. И, наконец, в MRI 2.2.0 появилась поддержка jemalloc
во время конфигурации! Хак с использованием LD_PRELOAD становится не нужен (а у меня он и не заработал, кстати).
Я побежал ставить jemalloc, а потом и MRI с включенным jemalloc. Наступил на пару грабель.
В Ubuntu и Homebrew jemalloc собран без профилировки. С самым свежим jemalloc 4.0.0, вышедшим в августе 2015 г.,
Ruby не собирается: некоторые гемы (pg) пугаются <stdbool.h>, включаемого в <jemalloc/jemalloc.h>. Зато с
версией 3.6.0 всё работает. Собрать Ruby можно по инструкции с помощью rbenv, хотя
я в итоге собирал сам:
cd ruby-2.2.3
./configure --with-jemalloc --prefix=/home/od/.rbenv/versions/2.2.3-dbg --disable-install-doc
make
make installДля Homebrew понадобится ещё ключ --with-openssl-dir=/usr/local/opt/openssl.
Этот Ruby работает как обычный. Но он реагирует на переменную среды MALLOC_CONF:
export MALLOC_CONF='narenas:1,stats_print:true'После завершения работы интерпретатора на stderr выдаётся обширная статистика
по выделенной памяти. С такой установкой я и запустил puma на ночь (с siege, конечно). К утру
RSS достиг 2 Гб. Нажав Ctrl-C и поглядев на статистику, я увидел, что общее количество памяти, выделенной
через jemalloc, примерно такое же. Эврика! Предположение об утечке в C-куче подтвердилось!
Профилировка и сбор статистики
Следующий вопрос был таков: в каком месте C-кода выделяется вся эта память?
Здесь помогла профилировка. Профилировщик, встроенный в jemalloc, запоминает адреса, с которых
делались вызовы malloc, подсчитывает, сколько с каждого адреса было выделено памяти, и сохраняет
статистику в дамп. Включить его можно через тот же MALLOC_CONF, указав ключ prof:true, тогда
после завершения работы процесса будет сгенерирован финальный дамп.
Дамп позже анализируется с помощью скрипта pprof.
К сожалению, pprof не смог нормально разобраться с адресами, выдав нечто вроде:
Total: 105.3 MB
43.5 41.3% 41.3% 43.5 41.3% 0x00007f384fd2b5f9
23.4 22.2% 63.6% 23.4 22.2% 0x00007f384fd2b773
...Пришлось самостоятельно вычитать начало кодового сегмента (информация о сегментах
печатается при завершении процесса) и запускать команду info symbol 0x2b5f9 в
gdb. Так я узнал, что этот адрес соответствует функции
objspace_xmalloc (она объявлена
как static, наверное, потому и не показывалась). Более-менее представительный профиль, снятый за пару
часов работы puma под нагрузкой, показал, что из этой функции было выделено
97.9 % всей памяти. Итак, утечка действительно имеет отношение к Ruby!
Укрепившись в области поиска, я решил исследовать статистические закономерности
выделяемых блоков. Дабы не мучаться с парсингом текстовой статистики, выдаваемой
jemalloc, сел и написал свой гем jemal. Основной
его функционал сокрыт в методе Jemal.stats, который возвращает всю интересную
статистику в одном большом хэше.
Осталось добавить небольшой кусок кода в приложение:
if ENV['JEMALLOC_STATS']
STDERR.puts "JEMALLOC_STATS enabled"
require 'jemal'
if Jemal.jemalloc_builtin?
STDERR.puts "jemalloc found"
Thread.new do
first = true
while true
sleep 5
stats = Jemal.stats
stats[:ts] = Time.now.utc.to_i
File.open(Rails.root + 'log/jemalloc.log', first ? 'w' : 'a') do |f|
f.puts stats.to_json
end
first = false
end
end
end
end…запустить puma и siege на ночь и по обычаю лечь спать.
К утру нарос неплохой log/jemalloc.log, и можно было браться за анализ. Здесь
незаменимую помощь оказала утилита jq. Для
начала я решил посмотреть, как растёт память:
jq '.ts,.allocated' log/jemalloc.log | paste - - > allocated.txtОбратите внимание, как здорово работает UNIX way! jq разбирает JSON в каждой строке
и попеременно выводит то значение ключа ts, то значение ключа allocated:
ts1
allocated1
ts2
allocated2
...Далее paste - - собирает это построчно, разделяя табуляцией:
ts1 allocated1
ts2 allocated2
...А такой файл уже годится на вход gnuplot:
set xdata time
set timefmt '%s'
set format x '%H:%M'
plot 'allocated.txt' using 1:($2/1048576) with lines title 'Allocated'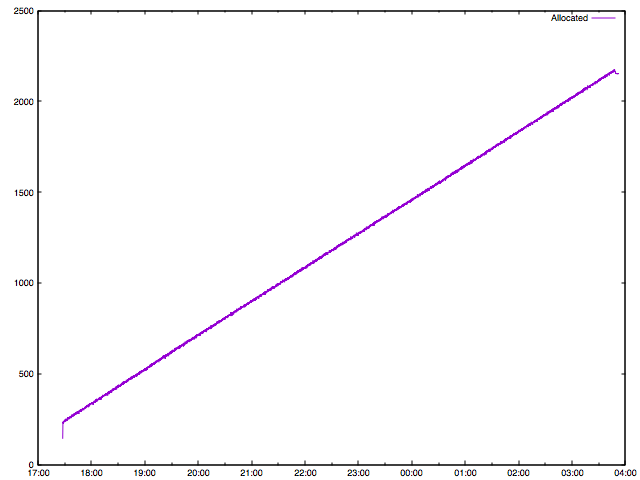
Рост от времени линейный! А что с размером блоков?
jq '.ts,.allocated,.arenas[0].small.allocated,.arenas[0].large.allocated' \
log/jemalloc.log | paste - - - - > allocated.txtjq умеет доставать данные даже из глубоко вложенных структур.
set xdata time
set timefmt '%s'
set format x '%H:%M'
plot 'allocated.txt' using 1:($2/1048576) with lines title 'Allocated', \
'' using 1:($3/1048576) with lines title 'Small', \
'' using 1:($4/1048576) with lines title 'Large'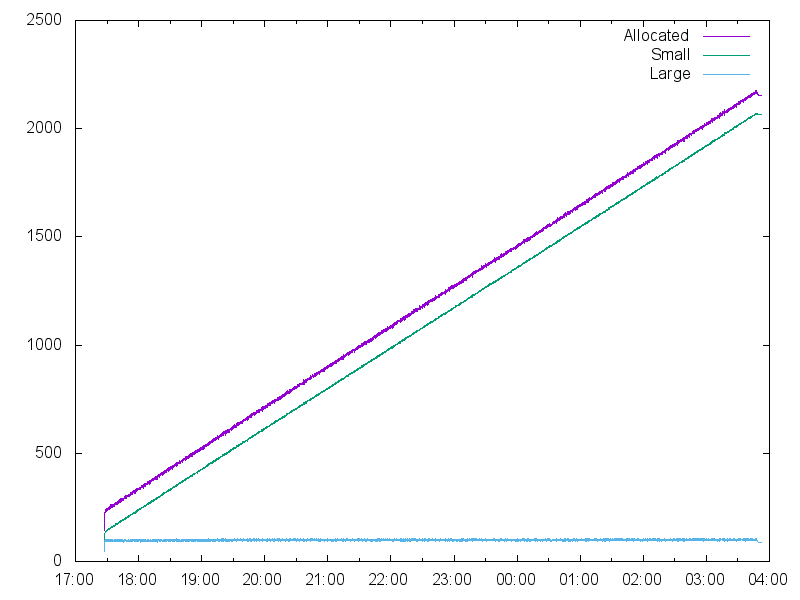
График красноречиво свидетельствует: утекают small-объекты. Но и это не всё: jemalloc предлагает статистику для разных размеров блоков! В классе small любой выделяемый блок путём округления размера вверх попадает в один из 28 фиксированных размеров: 8, 16, 32, 48, 64, 80, …, 256, 320, 384, …, 3584. Для каждого из них ведётся своя статистика. Приглядевшись к логу, я увидел аномальные значения для размера 320. Попробуем нарисовать и его:
jq '.ts,.allocated,.arenas[0].small.allocated,.arenas[0].large.allocated,.arenas[0].bins["320"].allocated' \
log/jemalloc.log | paste - - - - - > allocated.txtset xdata time
set timefmt '%s'
set format x '%H:%M'
plot 'allocated.txt' using 1:($2/1048576) with lines title 'Allocated', \
'' using 1:($3/1048576) with lines title 'Small', \
'' using 1:($4/1048576) with lines title 'Large', \
'' using 1:($5/1048576) with lines title 'Small (257..320)'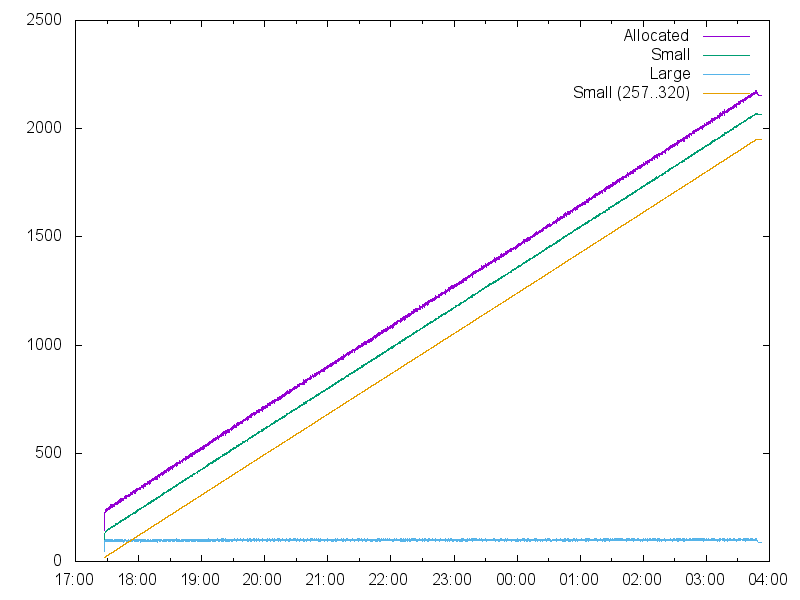
Ух ты! Память съедают объекты одного-единственного размера. Всё остальные составляют собой константу,
что следует из параллельности линий на графике. Что же происходит с размером 320?
Помимо общей суммы выделенной памяти для каждого размера jemalloc вычисляет
8 других показателей, в частности, количество выделений памяти (вызовов malloc)
и количество освобождений. Что с ними? Рисуем:
jq '.ts,.arenas[0].bins["320"].nmalloc,.arenas[0].bins["320"].ndalloc,.arenas[0].bins["256"].nmalloc,.arenas[0].bins["256"].ndalloc' \
jemalloc.log | paste - - - - - > malloc_dalloc.txtset xdata time
set timefmt '%s'
set format x '%H:%M'
plot 'malloc_dalloc.txt' using 1:2 with lines title '320 nmalloc', \
'' using 1:3 with lines title '320 ndalloc', \
'' using 1:4 with lines title '256 nmalloc', \
'' using 1:5 with lines title '256 ndalloc'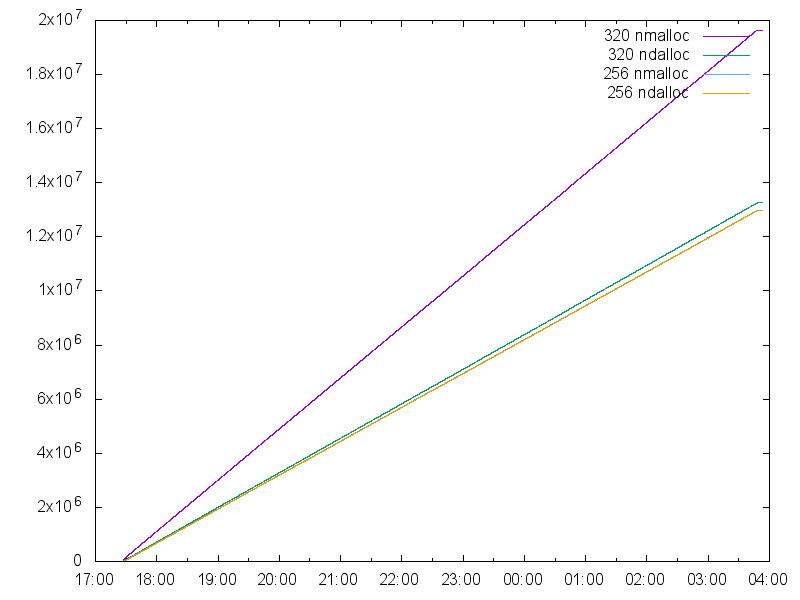
Для сравнения на графике приведены значения для блоков соседнего размера: 256. Видно, что голубая и оранжевая кривая слились воедино, что означает, что количество освобождений для размера 256 примерно соответствует количеству выделений. А вот для размера 320 количество выделений (фиолетовая кривая) уходит в отрыв от количества освобождений (зелёная кривая). Что окончательно подтверждает существование утечки памяти.
Откуда утекает?
Мы выжали из статистики всё, что могли. Осталось найти виновника утечки.
Тут я не нашёл ничего лучше, чем вставить отладочную печать в модуль gc.c.
Такими стали функции objspace_xmalloc и objspace_xfree:
static void *
objspace_xmalloc(rb_objspace_t *objspace, size_t size)
{
void *mem;
size_t orig_size = size;
size = objspace_malloc_prepare(objspace, size);
TRY_WITH_GC(mem = malloc(size));
size = objspace_malloc_size(objspace, mem, size);
objspace_malloc_increase(objspace, mem, size, 0, MEMOP_TYPE_MALLOC);
mem = objspace_malloc_fixup(objspace, mem, size);
if (size == 320) {
fprintf(stderr, "objspace_xmalloc: %zu => %p\n", orig_size, mem);
}
return mem;
}
static void
objspace_xfree(rb_objspace_t *objspace, void *ptr, size_t old_size)
{
#if CALC_EXACT_MALLOC_SIZE
ptr = ((size_t *)ptr) - 1;
old_size = ((size_t*)ptr)[0];
#endif
old_size = objspace_malloc_size(objspace, ptr, old_size);
if (old_size == 320) {
fprintf(stderr, "objspace_xfree: %p\n", ptr);
}
free(ptr);
objspace_malloc_increase(objspace, ptr, 0, old_size, MEMOP_TYPE_FREE);
}Чтобы не потонуть в море информации, я отказался от siege и стал запускать curl
вручную. Меня заинтересовало, сколько блоков утекает в процессе обработки одного запроса.
В код приложения была добавлена дополнительная middleware:
# lib/rack/memory_analyzer_middleware.rb
require 'jemal'
class MemoryAnalyzerMiddleware
def initialize(app)
@app = app
end
def call(env)
GC.start
st1 = Jemal.stats
puts "-------------------------"
res = @app.call(env)
GC.start
st2 = Jemal.stats
bin1 = st1[:arenas][0][:bins][320]
bin2 = st2[:arenas][0][:bins][320]
puts "MAM BEFORE: #{stats_line(bin1)}"
puts "MAM AFTER: #{stats_line(bin2)}"
res
end
def stats_line(bin)
delta = bin[:nmalloc]-bin[:ndalloc]
"Allocated #{bin[:allocated]} Mallocs #{bin[:nmalloc]} Dallocs #{bin[:ndalloc]} M-D #{delta} Nreqs #{bin[:nrequests]}"
end
end
# config/initializers/memanalyzer.rb
if ENV['MEMANALYZER']
require 'rack/memory_analyzer_middleware'
Rails.application.middleware.unshift MemoryAnalyzerMiddleware
endInitializer (а не config/application.rb) здесь нужен для того, чтобы middleware
встала в самую вершину стека.
Запустив несколько раз curl, я увидел что величина M-D прирастает с каждым
запросом на 80-90. Вместе с этим на stderr (и в лог благодаря tee)
стала валиться куча информации о выделяемых и освобождаемых блоках. Выкусив последнюю часть
лога между ------------------------- и MAM BEFORE ..., я прогнал её через
несложный скрипт:
#!/usr/bin/env ruby
require 'pp'
fname = ARGV.first
blocks = {}
File.open(fname, 'r') do |f|
f.each_line do |line|
case line
when /objspace_xmalloc: (\d+) => 0x([0-9a-f]+)/
blocks[$2] = $1.to_i
when /objspace_xfree: 0x([0-9a-f]+)/
blocks.delete $1
else
puts line
end
end
end
pp blocksИ вот они, адреса потенциальных утечек:
{"7fed15c08500"=>288,
"7fed15c0c4c0"=>296,
"7fed15c0d500"=>312,
"7fed15c0f440"=>264,
"7fed15c0f580"=>304,
# ещё 190 строк
"7fed195cee40"=>312,
"7fed195cf840"=>312,
"7fed195cfd40"=>312,
"7fed195cffc0"=>312,
"7fed195d0b00"=>312,
"7fed195d0d80"=>312,
"7fed195e1640"=>312}Оказалось довольно много блоков размера 312. О чём это говорит? Да ни о чём! Конечно, захотелось посмотреть на содержимое – тут помог gdb, которым я подключился прямо к живому процессу. Берём какой-нибудь адрес и смотрим, что там:
(gdb) x/312xb 0x7f1138a83340
0x7f1138a83340: 0x34 0xe1 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83348: 0x97 0xe2 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83350: 0xb8 0xe3 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83358: 0xd9 0xe4 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83360: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7f1138a83368: 0xf4 0xe6 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83370: 0x98 0xe8 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83378: 0x3c 0xea 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a83380: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7f1138a83388: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7f1138a83390: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7f1138a83398: 0xd6 0xef 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a833a0: 0xf7 0xf0 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a833a8: 0x2f 0xf2 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a833b0: 0xd9 0xf3 0xde 0x39 0x11 0x7f 0x00 0x00
0x7f1138a833b8: 0x04 0xf5 0xde 0x39 0x11 0x7f 0x00 0x00Похоже на кучу указателей. В Intel используется little-endian, поэтому
старший байт в конце, и первая строка представляет из себя число
0x7f1139dee134. Полезно? Что-то не очень.
Тогда мне захотелось увидеть backtrace вызовов, которые выделяют эти блоки. На просторах Интернетов был найден рабочий код для gcc:
#include <execinfo.h>
void print_trace(FILE *out, const char *file, int line)
{
const size_t max_depth = 100;
size_t stack_depth, i;
void *stack_addrs[max_depth];
char **stack_strings;
stack_depth = backtrace(stack_addrs, max_depth);
stack_strings = backtrace_symbols(stack_addrs, stack_depth);
fprintf(out, "Call stack from %s:%d:\n", file, line);
for (i = 1; i < stack_depth; i++) {
fprintf(out, " %s\n", stack_strings[i]);
}
free(stack_strings); // malloc()ed by backtrace_symbols
fflush(out);
}Условие в objspace_xmalloc дополнилось вызовом этой чудо-функции:
if (size == 320) {
fprintf(stderr, "objspace_xmalloc: %zu => %p\n", orig_size, mem);
print_trace(stderr, __FILE__, __LINE__);
}Я повторил всю последовательность действий, запустил скрипт обработки адресов, а потом стал по одному искать выявленные адреса в логе, ведь рядом с ними печатались backtrace.
И тут открылось…
objspace_xmalloc: 312 => 0x7fed195e1640
Call stack from gc.c:7394:
puma 2.11.3 (tcp://0.0.0.0:3000) [shuttlerock](+0x46e7a) [0x7fed31a6fe7a]
puma 2.11.3 (tcp://0.0.0.0:3000) [shuttlerock](ruby_xmalloc+0x2c) [0x7fed31a70077]
/home/od/.rbenv/versions/2.2.3-dbg/lib/ruby/gems/2.2.0/extensions/x86_64-linux/2.2.0-static/redcarpet-3.3.0/redcarpet.so(+0x7a00) [0x7fed17df0a00]Около десятка адресов засветились с redcarpet.so. Так вот кто съел всю нашу память!!!
Это оказался гем redcarpet — рендерер Markdown в HTML.
Проверка и починка
Дальше было дело техники. В консоли запустил 10000 рендерингов — утечка подтверждается. Сделал то же с гемом отдельно, без Rails – есть утечка!
Единственное место, где в native code гема выделялась память Ruby-средствами, нашлось
в функции rb_redcarpet_rbase_alloc, представляющей собой конструктор класса
Redcarpet::Render::Base, написанный на C. Эта функция выделяла память под структуру,
которая при сборке мусора не освобождалась. Быстрый гуглинг выявил пример
корректного написания такого конструктора в блоге tenderlove. Фикс оказался простым.
Бинго!
Выводы
- Наверное, можно было не тратить две недели. Сейчас я бы точно потратил меньше времени.
- Ложные пути уводят в сторону — приходится возвращаться. Кроме возни с дампами, я потратил некоторое
время на попытки настроить сборщик мусора с помощью переменных окружения. Единственное,
что мне из этого пригодилось:
RUBY_GC_HEAP_INIT_SLOTS=1000000. С такой настройкой наше приложение полностью влезает в кучу. - Кажется, в наше время можно отладить всё, что угодно. Количество полезных утилит и библиотек огромно. Если не получается, нужно просто пробовать дальше.
P.S.
15 сентября 2015. Здесь можно посмотреть, как выглядит график памяти, когда утечки нет.
23 сентября 2015. А вот перевод поста в англоязычной версии блога.
29 сентября 2015. Вышел фикс для Redcarpet.