Деплой на Heroku
Пролог
11:34:13. CTO: Ты деплоишь?
11:34:37. Разработчик 1: Деплою.
11:36:15. CTO: Деплоится?
11:36:21. Разработчик 1: Ага.
11:37:13. CTO: Задеплоилось?
11:37:16. Разработчик 1: Погоди, уже рестартится.
11:37:22. CTO: …Зарестартилось?
11:37:25. Разработчик 1: Да. Можешь сказать Максу, пусть посмотрит.
11:40:01. CTO: Макс говорит, что ничего не поменялось. Ты точно задеплоил?
11:40:48. Разработчик 1: Ну точно я задеплоил, блин. У меня работает. Хотя погоди-ка, что за…
11:41:03. Разработчик 2: О, ребята, вы тут деплоите что ли? А я свою ветку поставил деплоиться.
11:41:09. Разработчик 1: …!
11:41:14. CTO: …!
Это не придуманный диалог. Примерно такой чат состоялся у нас в Campfire в 2011 году.
Что тут скажешь? Процесс, затрагивающий многих, должен быть наглядным для всех! Именно поэтому в аэропортах рейсы показываются на больших заметных табло, а не только в маленьком терминальном окне авиадиспетчера.
Если мы уже собрались в этом чате, так давайте здесь и деплоить! И пусть все стадии и результат будут видны здесь же. Дальнейшая история расскажет, как я реализовал такую схему.
Вот как это работает в Slack-чате Shuttlerock:
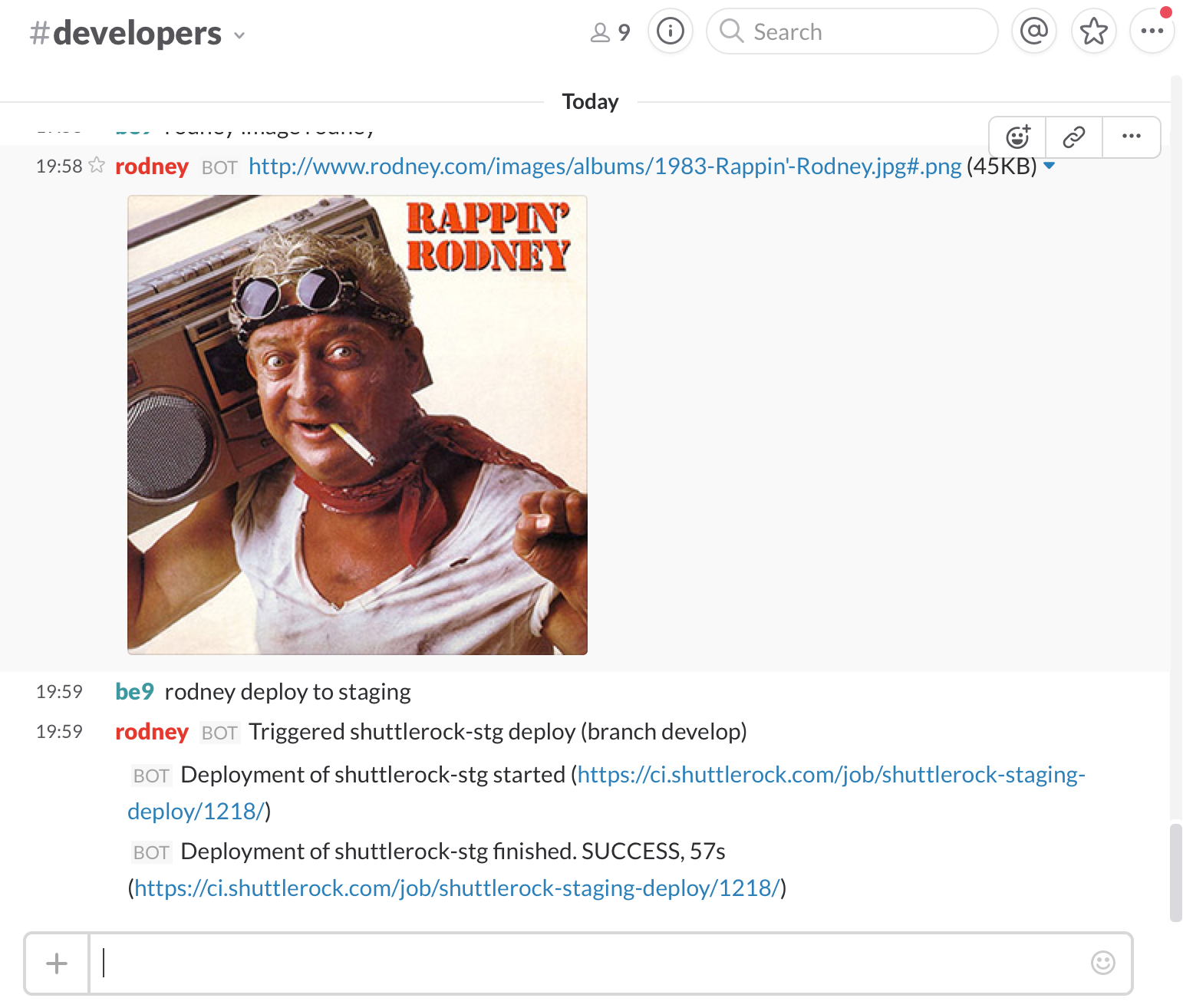
Возможно, моё решение окажется полезным и для вас!
Heroku
В проектах мы обычно используем Heroku. Как и всё на свете, сервис Heroku имеет свои преимущества и недостатки. Он обходится дороже, чем аренда виртуального сервера на DigitalOcean, но это плата за то, что DevOps-инженеры Heroku не спят ночью, а вы можете спать.
Деплой в Heroku устроен просто: git push – и понеслась. Через некоторое время
приложение уже перезапустилось и работает. По крайней мере, в теории. А на
практике есть некоторые нюансы, с которыми приходится иметь дело.
Нюанс 1. Assets
Да-да, это CSS, JS и их друзья. Если вы, не прикладывая специальных усилий, задеплоите
приложение на Heroku, оно, конечно, будет работать. Но все assets будут отдаваться клиентам
из Ruby, то есть ваши недешёвые dynos будут изображать из себя Apache.
Во-первых, это медленно (настоящие Apache и nginx справятся гораздо быстрее). Во-вторых,
пока код Rack заталкивает в сетевой буфер содержимое скомпилированного
application.js, входящие запросы стоят и ждут. Очевидно, такая схема подойдёт
лишь для сайта вашей тёщи, но не более.
Поэтому все homo, которые sapiens, для хранения и отдачи assets используют CDN. Например, закачивают скомпилированные assets на S3 и раздают их оттуда через CloudFront. Аналогично с Rackspace и прочими облачными платформами. Нет для статики ничего лучше, чем CDN, – можно принять это за аксиому.
Заметим, что для правильной генерации URL для assets приложение нуждается
в файле-манифесте, который создаётся в процессе выполнения rake assets:precompile.
В Rails 4 этот файл лежит в каталоге public/assets и имеет примерно следующий вид:
// public/assets/.sprockets-manifest-9b2e86e85245c42f19250388ba3e1a45.json
{
"files": {
"application-3dda9c3d8b35165ec9de63f4b471dc4ce898f16443b1c132aa5049128d8e9a1c.js": {
"logical_path": "application.js",
"mtime": "2015-10-07T11:22:21+06:00",
"size": 341219,
"digest": "3dda9c3d8b35165ec9de63f4b471dc4ce898f16443b1c132aa5049128d8e9a1c",
"integrity": "sha256-PdqcPYs1Fl7J3mP0tHHcTOiY8WRDscEyqlBJEo2Omhw="
},
// ...
},
"assets": {
"application.js": "application-3dda9c3d8b35165ec9de63f4b471dc4ce898f16443b1c132aa5049128d8e9a1c.js",
// ...
}
}Благодаря манифесту конструкция <%= javascript_include_tag :application %>
генерирует ссылку на имя файла с длинным шестнадцатеричным хвостом. Если этот файл
был предварительно загружен на CDN, всё работает.
Как это всё увязывается с Heroku? По умолчанию в процессе деплоя
Heroku выполняет команду rake assets:precompile, которая наполняет каталог public/assets
скомпилированными assets, включая и манифест. Но как файлам попасть на CDN? Как
обеспечить стопроцентную актуальность манифеста?
На то был создан гем asset_sync. Он
добавляет свою rake task, которая срабатывает после rake assets:precompile и заливает
всё на S3. Таким образом, в процессе деплоя после компиляции прямо с билд-сервера Heroku
запускается синхронизация с S3.
К сожалению, это решение оказывается так себе. Оно очень сильно удлиняет время деплоя, особенно в больших проектах. Компилятор assets, вообще-то, умный. Он кеширует свои результаты и заново работу делать не будет. Посмотрите на результаты локального запуска:
rm -rf public/assets
time bin/rake assets:precompile
#> Writing ..... (много строк пропущено)
#> bin/rake assets:precompile 0,19s user 0,10s system 5% cpu 5,191 total
time bin/rake assets:precompile
#> bin/rake assets:precompile 0,16s user 0,07s system 28% cpu 0,807 totalВ процессе второго запуска не было изменено ничего. Однако на Heroku этим кэшем воспользоваться не получится, потому что билд-сервер каждый раз работает с чистого листа. Полная компиляция и синхронизация будет делаться каждый раз, даже если вы assets не трогали. И это напрягает!
Нюанс 2. Миграции
Если вы используете SQL-базу данных, периодически возникает необходимость прогона
миграций. Но и здесь у Heroku всё непросто. Автоматически ничего не происходит,
вам нужно вызывать heroku run rake db:migrate самостоятельно. Но: исполнить
эту команду можно только после деплоя, когда соответствующие файлы в db/migrate
будут на месте. Соответственно, возможен случай, когда только что задеплоенный Ruby-код будет
ссылаться на атрибут в БД, которого ещё нет (миграция не успела выполниться);
тогда пользователь увидит 500-ю ошибку.
Чтобы избежать этой неприятной ситуации, Heroku предлагает перед деплоем включать режим maintenance. Полный скрипт деплоя будет выглядеть так:
heroku maintenance:on
git push heroku master
heroku run rake db:migrate
heroku maintenance:off
heroku restartheroku restart необходим для того, чтобы схема БД была перечитана. В
production-режиме она читается один раз на старте, и если в таблице users
не было поля age, то методы User#age и User#age= не будут созданы. И даже
после того, как миграция пройдёт и колонка age появится, любой код, вызывающий
эти методы, так и будет падать.
К сожалению, даже в этой схеме между выполнением heroku maintenance:off и
heroku restart может пролезть какой-нибудь неудачливый пользователь и
схлопотать свою 500-ю. Но иначе никак.
А теперь давайте представим, что assets компилируются и синхронизируются несколько минут — вполне реальные цифры для большого приложения. И всё это время мы в режиме maintenance!..
Путь к желаемой системе
Итак, мы очертили круг проблем:
- Наглядность процесса деплоя.
- Компиляция assets и заливка на CDN.
- Запуск миграций.
Поразмышляв, я пришёл к следующему решению:
- Весь процесс деплоя работает внутри Jenkins, работающего на выделенном VPS-сервере.
- Assets полностью компилируются и заливаются на S3 перед деплоем. Если изменений
не было (что можно отследить по истории git), то ничего не делается (а это очень быстро).
Если изменения-таки были,
rake assets:precompileиспользует локальный кэш, что убыстряет компиляцию. - Запуск деплоя происходит через Hubot — бота, висящего в чате и взаимодействующего с Jenkins. Он же оповещает об успешном или неуспешном завершении деплоя.
- Прогон миграций является опциональным. Вводится два режима деплоя: обычный (приведённый выше полный скрипт с включением режима maintenance) и быстрый, когда миграции не прогоняются вообще.
Таким образом, система состоит из следующих частей:
- Hubot.
- Кастомный скрипт для Hubot, реализующий команду deploy и взаимодействующий с Jenkins.
- Настроенный и работающий Jenkins с соответствующими сборками.
- Bash-скрипт
bin/deployв исходном коде приложения. Его в процессе сборки запускает Jenkins. - Модуль для синхронизации assets с S3 внутри приложения.
Давайте немного обсудим эти отдельные части.
Hubot
Я влюбился в Hubot с первого взгляда и использую его в каждом проекте. Мои любимые
команды помимо deploy — это image и excuse.
По сути, Hubot обеспечивает удобный программный интерфейс к вашему чату в Slack (HipChat, Campfire). Написать JS-код, который будет реагировать на команды, нетрудно.
Сам Hubot легко деплоится на Heroku.
Jenkins
Jenkins – это тот ещё Java-монстр. Однако он стабильно работает и к нему есть очень много плагинов. Свой плагин написать не так просто, как для Hubot, но обойдёмся. Итак, что же хорошего нам даёт Jenkins?
- Прозрачная работа с Git. Jenkins может склонировать репозиторий, выбрать и обновить нужную ветку.
- История сборок с логами. Если что-то не работает, результат прогона будет доступен всем разработчикам, допущенным в Jenkins.
- Очередь сборок. Если поступило подряд две команды на деплой, вторая встанет в очередь и подождёт, пока первая закончит свою работу. Если вторая была дана случайно, можно успеть зайти в веб-интерфейс Jenkins и отменить её.
- Параллельность сборок. Если у вас несколько приложений или версий одного приложения (staging, production), деплой будет идти параллельно.
По сути, Jenkins — это супер-богатая оболочка для запуска bash-скриптов.
Настройка
Перейдём же к настройке и конфигурированию. Ниже будет предполагаться, что Heroku-приложение называется coolapp.
Jenkins
Установить Jenkins несложно. В последнем проекте я для этого использовал ansible, взяв готовую роль Stouts.jenkins. Нам понадобятся следующие плагины:
- GIT plugin.
- Build Authorization Token Root Plugin. Нужен для того, чтобы можно было HTTP-запросом запустить сборку (деплой) снаружи.
- Notification plugin. Потребуется для уведомления Hubot о процессе сборки.
Я также ставлю Green Balls для красоты, ChuckNorris Plugin для прикола, Matrix Authorization Strategy Plugin для удобного управления доступом, Credentials Plugin для задания дополнительных ключей доступа к репозиториям и SCM Sync Configuration Plugin для сохранения конфигов Jenkins в git.
У того пользователя, под которым будет работать Jenkins (обычно это jenkins),
должны быть установлены интерпретаторы Ruby всех необходимых версий. Для этого
оказалась полезной ansible-роль zzet.rbenv.
Убедившись, что всё работает, можно приступать к созданию сборки. Дадим ей осмысленное имя:

Каждая версия приложения (staging, production, …) потребует отдельной сборки. Затем добавим нотификацию:
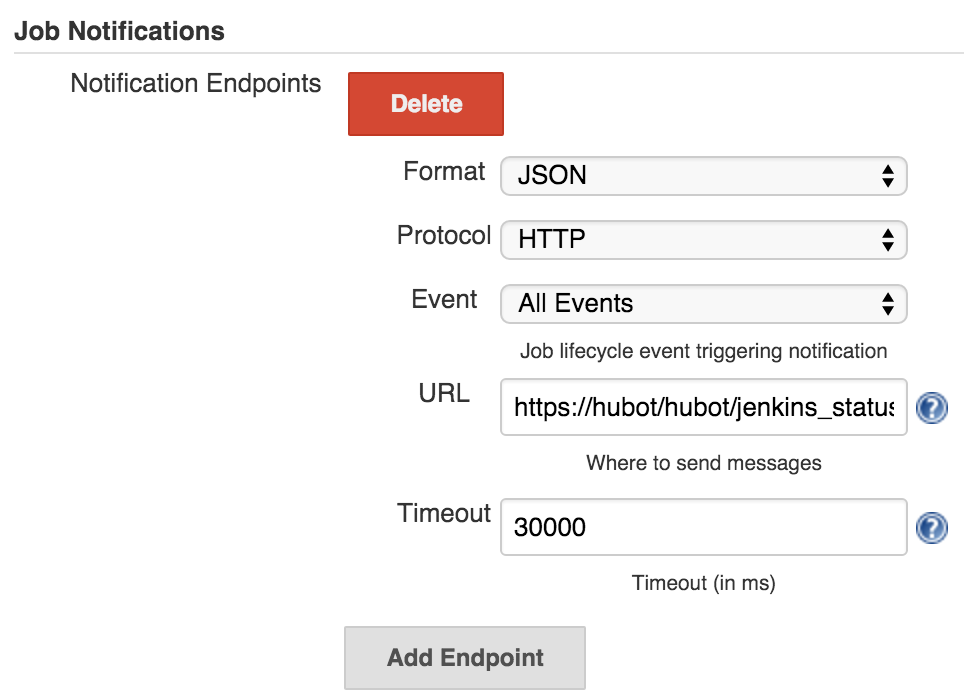
В поле URL должен находиться полный адрес Hubot со специфическим путём:
например, https://my-hubot-instance.herokuapp.com/hubot/jenkins_status.
Ниже нужно поставить галку «Параметризованная сборка». Параметры, которые мы создадим, с одной стороны, будут доступны скрипту сборки как переменные окружения, а, с другой стороны, их можно будет передавать извне, запуская сборку посредством HTTP POST-запроса. Понадобятся следующие параметры:
| Имя | Тип | Значение по умолч. | Описание |
|---|---|---|---|
| APP | Строка | coolapp-staging |
Имя приложения Heroku |
| BRANCH | Строка | master |
Имя ветки |
| DEPLOYER | Строка | (пусто) | Инициатор деплоя |
| QUICK | Булев. | выкл. | Быстрый режим — без миграций |
| EXTRA | Строка | (пусто) | Доп. параметры |
В разделе «Source Code Management» следует выбрать Git и указать адрес репозитория,
а в поле выбора ветки поставить origin/$BRANCH:
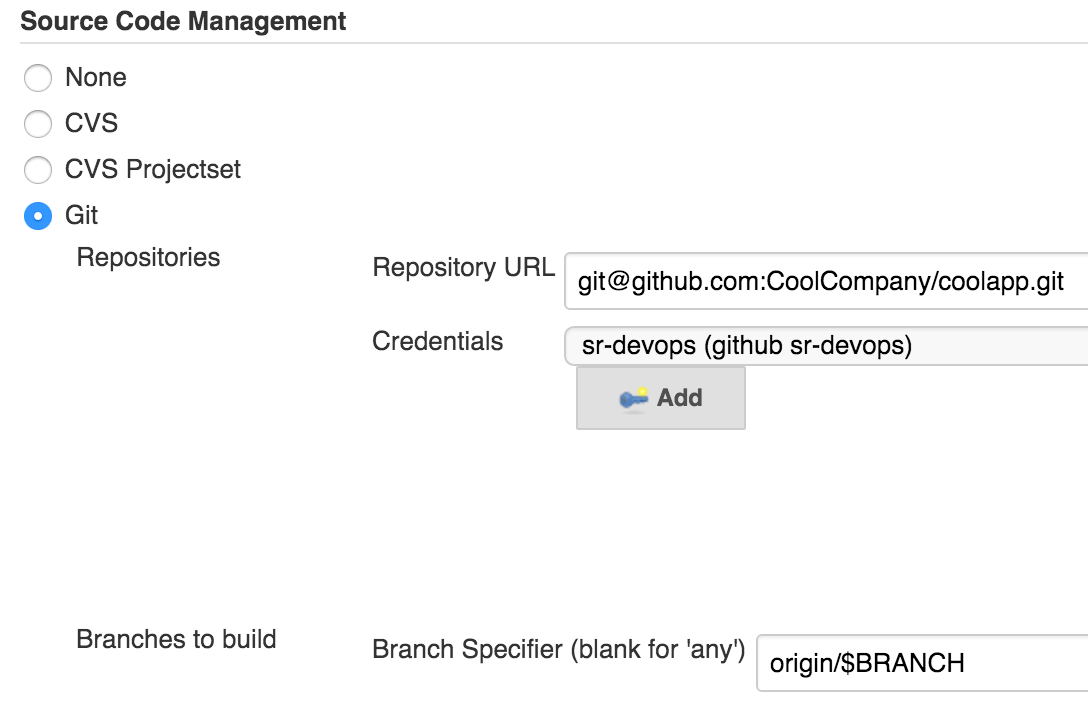
Это позволит нам деплоить любую ветку, которая есть в Git.
В разделе «Build Triggers» задайте токен для внешней связи, а все остальные галки отключите:

Останется лишь добавить шаг сборки («Execute Shell»):
# Используем динамическое задание версии Ruby. Не забудьте указать версию
# в вашем Gemfile! Например, ruby '2.2.3'
ruby_version=`grep '^ruby' Gemfile|cut -d "'" -f 2`
# Домашний каталог пользователя jenkins – /var/lib/jenkins. Если у вас другой,
# поправьте.
export PATH=/var/lib/jenkins/.rbenv/versions/$ruby_version/bin:/var/lib/jenkins/.rbenv/shims:$PATH
export HOME=/var/lib/jenkins
# Делаем параметр EXTRA доступным внутри bin/deploy.sh
export EXTRA
# А это ключи доступа для закачки assets на S3:
export AWS_ACCESS_KEY_ID=<ключ>
export AWS_SECRET_ACCESS_KEY=<секретный ключ>
export AWS_BUCKET=coolapp-prod-assets
# Задайте правильное имя окружения
export RAILS_ENV=staging
# В некоторых версиях Rails команда rake assets:precompile зачем-то требует
# соединение с БД. Оказалось легче уступить, для чего я создал пустую БД
# и пользователя jenkins с паролем jenkins.
export DATABASE_URL=postgresql://jenkins:jenkins@127.0.0.1/jenkins_empty
# Пришлось столкнуться и с тем, что Devise требует ключ. Хотя мы всего лишь
# делаем rake assets:precompile! Как гласит мудрость, зануде легче отдаться…
export DEVISE_SECRET_KEY=fb02df94e6fb4
# Эти команды будут полезны, если что-то не будет работать. Раскомментируйте
# для отладки:
#env
#gem env
#bundle env
if [[ -f bin/deploy.sh ]]; then
exec bin/deploy.sh
else
false
fiИтак, здесь мы настраиваем среду и передаём управление скрипту
bin/deploy.sh.
К слову сказать, если вы создаёте вторую, третью и т.д. сборку, не забивайте всё заново, а воспользуйтесь режимом копирования:
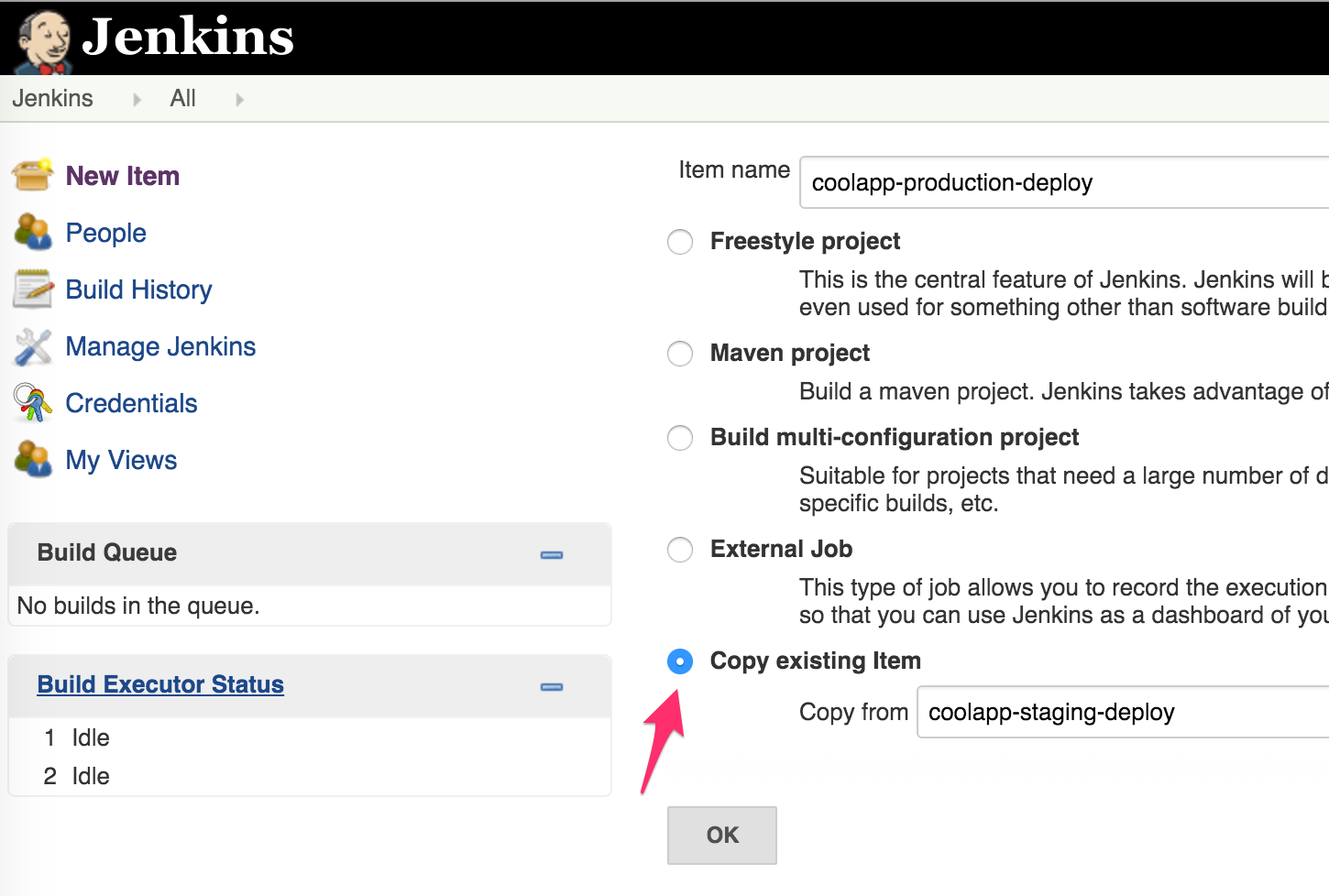
А пока возьмёмся за Hubot.
Настройка Hubot
Hubot ставится по инструкции. Кстати, подберите подходящее имя для бота вместо «hubot». Например, в Shuttlerock у нас его зовут rodney.
В каталог scripts нужно будет добавить файл deploy.coffee. Эта версия работает для Slack, для других адаптеров могут потребоваться минимальные правки.
В deploy.coffee вам потребуется поменять только одну строку:
APPS = ['production', 'staging']Укажите здесь все приложения и/или их версии, которые вы будете деплоить. Например, эта строка могла бы выглядеть так:
APPS = ['production', 'staging', 'monitoring production', 'monitoring staging']Здесь подразумеваются две версии основного приложения и две версии приложения monitoring.
Остальные настройки делаются посредством изменения переменных окружения у инстанса Hubot. Рассмотрим настройки, необходимые для работы деплоя.
-
Переменная
HUBOT_JENKINS_URLдолжна содержать полный адрес Jenkins (например,https://jenkins.example.com). -
Для
HUBOT_JENKINS_BUILD_TOKENзадайте значение, которое вы указывали при конфигурации сборки (в нашем примере это0W5CT73cFV4ia89N9Sa87S644v3twA9P). Предполагается, что этот токен одинаков для всех приложений и их версий. -
Теперь для каждого приложения из массива
APPSзадайте четыре переменных:HUBOT_PRODUCTION_APP. Это имя Heroku-приложения. В нашем примереcoolapp-staging.HUBOT_PRODUCTION_DEFAULT_BRANCH. Ветка, которая будет деплоиться по умолчанию (если явно не указана). Например,master.HUBOT_PRODUCTION_JOB. Имя сборки у Jenkins. У нас этоcoolapp-staging-deploy.HUBOT_PRODUCTION_ACL. Эта переменная управляет доступом к деплою. Здесь нужно задать либо список E-mail допущенных пользователей через запятую, либоeveryone. Реальные E-mail адреса можно посмотреть с помощью команды ботаhubot show users.
Имена переменных получаются из имени приложения. Например, для monitoring staging
они будут называться HUBOT_MONITORING_STAGING_APP и т.д.
Итак, если всё сконфигурировано верно, команда боту (hubot deploy to staging)
запустит на Jenkins сборку с соответствующими параметрами. Теперь давайте
посмотрим в самую сердцевину процесса — на скрипт deploy.sh.
bin/deploy.sh
Скрипт находится в том же gist, но давайте разберём, что там происходит. Пойдём по отдельным функциям.
set_extra_flags
set_extra_flags() {
if [[ "$EXTRA" =~ 'reupload assets' ]]; then
export CLOUD_ASSETS_REUPLOAD=1
fi
if [[ "$EXTRA" =~ 'recompile assets' ]]; then
export CLOUD_ASSETS_RECOMPILE=1
fi
if [[ "$EXTRA" =~ 'cleanup assets' ]]; then
export CLOUD_ASSETS_REMOTE_DELETE=1
fi
if [[ "$EXTRA" =~ 'skip heroku' ]]; then
export SKIP_HEROKU=1
fi
if [[ "$EXTRA" =~ 'clear cache' ]]; then
export CLEAR_CACHE=1
fi
}Здесь видно, как используется «хвост» команды боту: в нём можно передать
дополнительные параметры. Просто команда hubot deploy to staging —
это одно. А если вы наберёте hubot deploy to staging and recompile assets and clear cache,
будут установлены переменные CLOUD_ASSETS_RECOMPILE и CLEAR_CACHE, что повлияет на процесс
(см. дальше).
compile_assets
compile_assets() {
current_sha=`git log -n 1 --pretty=format:%H app/assets vendor/assets`
if [[ -f public/assets/CURRENT_SHA && `cat public/assets/CURRENT_SHA` == $current_sha && "$CLOUD_ASSETS_REUPLOAD" == '' && "$CLOUD_ASSETS_RECOMPILE" == '' ]]; then
echo "Assets did not change (SHA $current_sha)"
else
echo "Recompiling assets"
bundle install --quiet --without=test
rm -rf public/assets
time bundle exec rake assets:precompile cloud_assets:sync
echo $current_sha > public/assets/CURRENT_SHA
fi
}В файле public/assets/CURRENT_SHA лежит последний коммит, изменявший содержимое app/assets или vendor/assets (если
ваши assets лежат где-то ещё, добавьте эти каталоги в аргументы git log). Если
изменений не было, то ничего перекомпилироваться не будет.
В противном случае происходит перекомпиляция (для надёжности выполняется
rm -rf public/assets, хотя это и не является необходимым) и заливка на S3.
Чтобы заливка работала, добавьте в исходный код проекта файлы
lib/tasks/cloud_assets.rake
и lib/fog_cloud_assets.rb.
Для работы последнего также понадобится гем fog_aws, не забудьте его добавить в Gemfile:
gem 'fog-aws', require: 'fog/aws'Модуль FogCloudAssets осуществляет инкрементальную закачку файлов на S3.
Если режим recompile assets, как мы видели выше, осуществляет полную перекомпиляцию,
то reupload assets делает полную закачку на S3: заливается даже то, что уже есть.
А cleanup assets удаляет все assets, которые отсутствуют в текущем манифесте.
save_deploy_information и commit
Из-за того, что мы компилируем assets до деплоя, встаёт вопрос, как обеспечить
наличие актуального манифеста в задеплоенном коде. Я
решил этот вопрос так: при каждом деплое создаётся временная ветка,
куда в public/assets коммитится файл манифеста, а при деплое вызывается
git push --force. Heroku же, увидев этот манифест, не будет
вызывать rake assets:precompile.
Это не очень элегантно, зато даёт новые возможности. Функция save_deploy_information,
например, генерирует файл lib/deploy_info.rb следующего формата:
module DeployInfo
BRANCH='feature/5852-core-can-upload-to-boards-via-the-api-when-submissions-false'
GIT_COMMIT='833a167e8bfd747816eb7337a45394f288ce813f'
BUILD_NUMBER='1217'
BUILD_ID='1217'
DEPLOYER='dave'
def message
return @message if defined?(@message)
text = File.read(__FILE__)
text =~ /[_]_END__(.*)$/m
@message = ($1 || '').strip
end
module_function :message
end
__END__
commit 833a167e8bfd747816eb7337a45394f288ce813f
Author: John Doe <johndoe@example.org>
Date: Thu Nov 12 18:02:04 2015 +0300
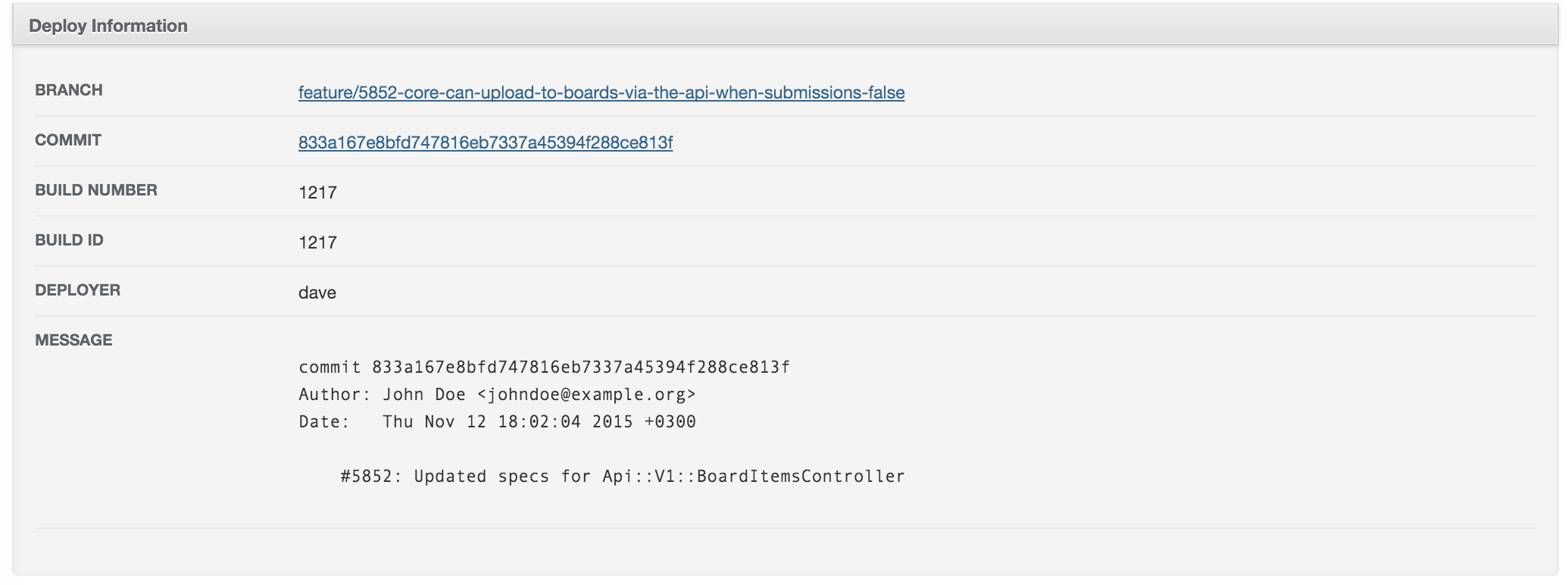
#5852: Updated specs for Api::V1::BoardItemsControllerА это позволяет легко понять, что именно задеплоено. Мы используем ActiveAdmin:
# app/admin/dashboards.rb
ActiveAdmin.register_page "Dashboard" do
content do
# ...
columns do
# ...
column do
panel "Deploy Information" do
require 'deploy_info'
github = "https://github.com/CoolCompany/coolapp/"
attributes_table_for DeployInfo do
row('Branch') { link_to DeployInfo::BRANCH, "#{github}tree/#{DeployInfo::BRANCH}" }
row('Commit') { link_to DeployInfo::GIT_COMMIT, "#{github}commit/#{DeployInfo::GIT_COMMIT}" }
row('Build Number') { DeployInfo::BUILD_NUMBER }
row('Build ID') { DeployInfo::BUILD_ID }
row('Deployer') { DeployInfo::DEPLOYER }
row(:message) { pre DeployInfo.message }
end
end # panel
end # column
end # columns
end # contentПолучается довольно красиво:
Чтобы ActiveAdmin не падал при локальном запуске приложения, положите в дерево исходных кодов
такой lib/deploy_info.rb:
# NOTE: Этот файл будет перезаписан в процессе деплоя!
module DeployInfo
BRANCH=`git rev-parse --abbrev-ref HEAD`.strip
GIT_COMMIT=`git rev-parse HEAD`.strip
BUILD_NUMBER='dev'
BUILD_ID='dev'
DEPLOYER=`git config user.name`.strip
def message
`git log -1 --pretty=medium`.strip
end
module_function :message
endРассмотрев отдельные детали, перейдём к изучению общей логики деплоя.
Основная логика bin/deploy.sh
set_extra_flags
compile_assets
save_deploy_information
commit
if [ "$QUICK" = "true" ]; then
if [[ "$SKIP_HEROKU" == '' ]]; then
git_push
else
echo "Skipping heroku push as requested"
fi
#if [[ "$CLEAR_CACHE" == '1' ]]; then
# echo "Clearing cache per request"
# heroku run rake cache:clear --app $APP
#fi
echo "QUICK mode, not running migrations"
else
if [[ "$SKIP_HEROKU" == '' ]]; then
heroku maintenance:on --app $APP
git_push
heroku run rake db:migrate --app $APP #cache:clear db:migrate --app $APP
heroku maintenance:off --app $APP
heroku restart --app $APP
else
echo "Skipping heroku push as requested"
fi
fiЗдесь в зависимости от параметра QUICK мы идём либо по короткому, либо по длинному пути.
Помимо этого показаны следующие вещи:
- Режим
skip herokuпозволяет скомпилировать и залить assets, но не трогать Heroku. Крайне редко, но бывает нужно. - У нас в текущем проекте
rake cache:clearвызываетRails.cache.clear. В закоментированной части показано, как этим пользоваться. Полный деплой по умолчанию вызываетcache:clearвместе сdb:migrate, а в быстром режиме можно сказать боту... and clear cache.
Следуя этой логике, можно легко добавлять собственные флаги для деплоя.
Для этого не придётся трогать ни Hubot, ни Jenkins, а лишь добавить обработку
в bin/deploy.sh.
Инструкция по пользованию командой deploy
Итак, вы всё настроили. Что можно теперь делать?
hubot deploy to production деплоит production (используется ветка по умолчанию).
hubot quick deploy feature/something-really-cool to staging деплоит указанную ветку (feature/…) на staging
в быстром режиме, без прогона миграций.
hubot deploy to production and recompile assets деплоит production, обязательно
перекомпилируя assets, даже если они с прошлого раза не менялись.
hubot disable deploys to staging временно запрещает деплой на staging (полезно,
если ведутся технические работы или вы глубоко в отладке и не хотите,
чтобы вам мешали). Можно указать причину:
hubot disable deploys to staging because it hurts.
hubot enable deploys to staging включает возможность деплоя обратно.
Обратите внимание, что для устойчивой работы полезно подключить к Hubot хранилище Redis с помощью плагина hubot-redis-brain.
Заключение
Получилась классная модульная система деплоя! Её преимущества для Rails:
- Удобный и управляемый деплой на Heroku.
- Компиляция assets происходит отдельно и не замедляет деплой. Если assets не менялись, на компиляцию и синхронизацию время не тратится вообще.
Но система не привязана к Rails! Общие преимущества для всех технологий:
- Все понимают, что происходит.
- Сохраняется история успешных и неуспешных прогонов.
- Деплоить может любой человек, кому это разрешено, в т.ч. новичок или тестировщик, которому трудно и долго устанавливать, настраивать и обновлять локальные зависимости (Heroku Toolbelt, Ruby, bundler, node.js и проч.).
- Деплоить можно любые ветки Git.
- Соответствующий скрипт несложно написать для любой технологии.
В Shuttlerock мы стали деплоить с помощью системы все активные проекты. Например, для деплоя приложения на angular.js с помощью bower и gulp нужно было лишь написать соответствующий скрипт.
Мои коллеги говорят, что это самая лучшая система, которую им доводилось использовать. Я им верю 😄 Попробуйте и вы!